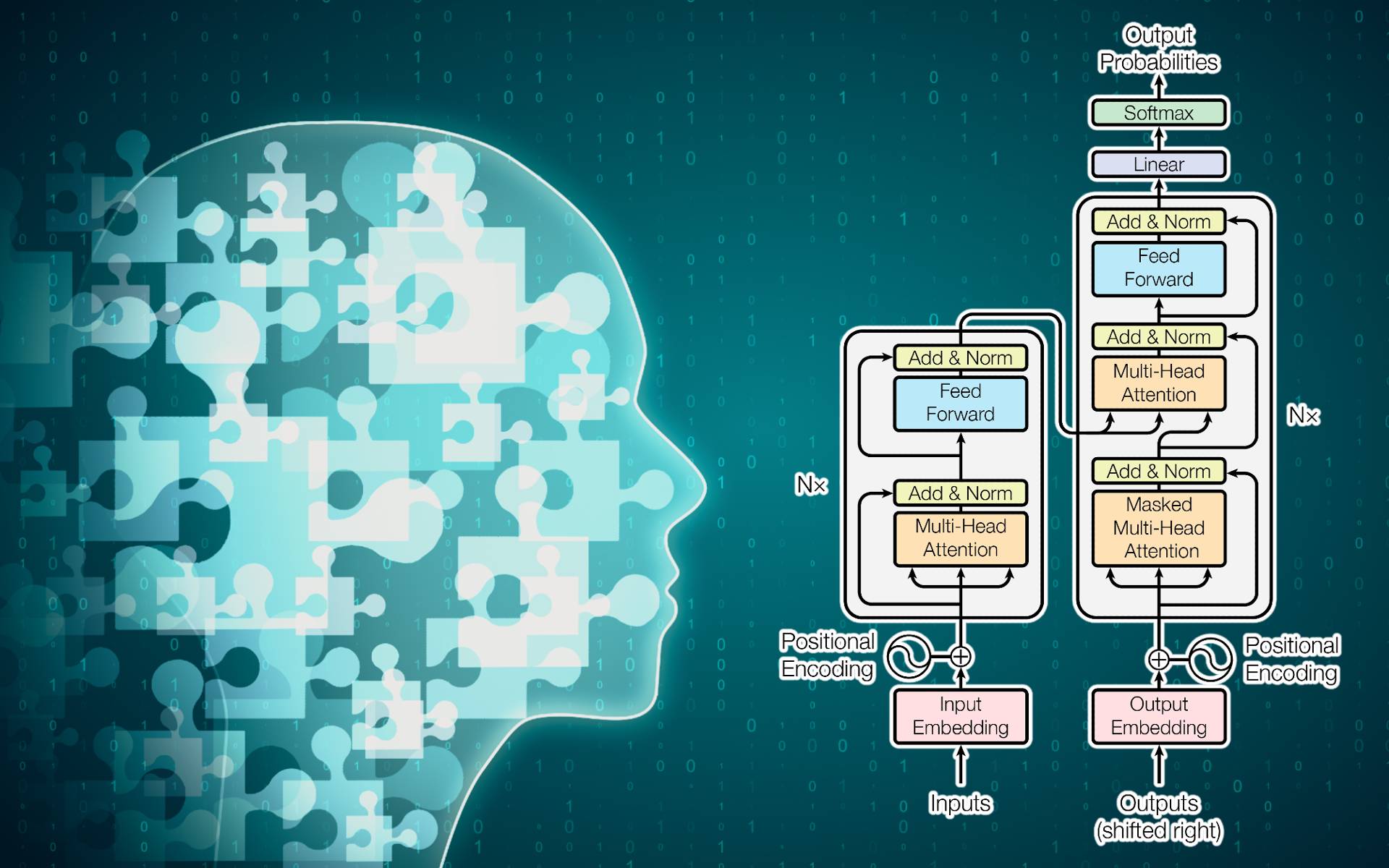
Nghiên cứu của kỹ sư Apple: AI không thể tư duy toán học vì không hiểu bản chất, dễ xao nhãng
Lý do nhắc đến khả năng này, và nghiên cứu về nó cũng dễ hiểu. Trong thời gian qua, khả năng lý luận và tư duy của những hệ thống machine learning, mô hình ngôn ngữ hay chatbot AI đã trở thành thứ được nhiều tập đoàn, từ OpenAI cho tới Google quảng cáo rất mạnh, để từ đó khắc họa tiềm năng trở thành một trợ lý ảo thông minh phục vụ cho nhu cầu sử dụng hàng ngày của hàng tỷ người trên thế giới, thông qua mọi thiết bị từ smartphone cho đến laptop, rồi sau này là cả kính thông minh…
Nhưng, vừa rồi đã có 6 kỹ sư của Apple thực hiện một công trình nghiên cứu, xác định khả năng tư duy lý lẽ toán học và logic của một vài LLM phổ biến hiện tại. Kết quả nghiên cứu cho thấy, khả năng đang được quảng cáo rất mạnh từ các tập đoàn công nghệ và startup AI, xét trên ví dụ một số LLM phổ biến hiện giờ thực tế tương đối kém, và không đáng tin cậy.
Tình trạng này được mô tả thông qua kết quả thử nghiệm mới, không khác biệt nhiều, thậm chí là ủng hộ những kết quả thử nghiệm trước đây của các nhà nghiên cứu khác. Những nghiên cứu này đều chỉ ra cùng một điểm: Cách vận hành tạo sinh nội dung bằng xác suất của các LLM không thể giúp mô hình AI hiểu được những ý tưởng toán học cơ bản, những thứ cần thiết để máy móc có khả năng tư duy lý luận toán học một cách đáng tin cậy.
Nói theo cách của các kỹ sư Apple thì là như thế này: “Những LLM hiện tại không có khả năng lý luận logic thực sự. Thay vào đó, chúng chỉ bắt chước những bước tư duy đã học được thông qua dữ liệu huấn luyện.”
Đổi đề bài
Để đi đến được kết luận như thế này, 6 nhà nghiên cứu của Apple sử dụng gói dữ liệu bài kiểm tra với 8000 câu hỏi toán học cấp trung học, gọi là GSM8K. Gói bài kiểm tra này là một trong số những công cụ benchmark tiêu chuẩn để đánh giá khả năng tính toán của những LLM hiện đại. Nhưng thay vì cứ để những mô hình ngôn ngữ phổ biến giải quyết những bài toán trong gói GSM8K, các nhà nghiên cứu sử dụng một giải pháp mới, thay đổi một phần dữ kiện các bài toán.
Chẳng hạn như câu hỏi “Sophie có 31 viên gạch đưa cho em” thì đổi thành “Bill có 19 viên gạch đưa cho anh”. Thay đổi những dữ kiện nhỏ này giải quyết được hai vấn đề. Thứ nhất là dữ liệu không bị can thiệp, và bản chất độ khó của bài toán cũng không bị ảnh hưởng, nghĩa là đáng lẽ ra các LLM vẫn sẽ phải giải quyết những bài toán ấy một cách dễ dàng.
Thế nhưng sau khi thay đổi dữ kiện các câu hỏi toán học, các nhà nghiên cứu phát hiện ra rằng, trong số 20 LLM được coi là phổ biến và mạnh nhất hiện tại, từ những giải pháp chạy local cho tới cả giải pháp chạy trên máy chủ như GPT-4o, tỷ lệ đưa ra lời giải chính xác của mỗi LLM sau khi chúng phải tư duy logic giải toán giảm từ 0.3% đối với GPT-4o, có lúc lên tới 9.2% đối với Mistral 7B.
Khác biệt về tỷ lệ đưa ra câu trả lời đúng của từng LLM đối với gói câu hỏi GSM8K cũng khác biệt trong 50 lượt chạy benchmark GSM-Symbolic, khi mỗi lần, các nhà khoa học lại thay đổi dữ kiện trong từng bài toán một cách thủ công và cẩn trọng. Một LLM có thể tạo ra kết quả benchmark tính toán đúng sai chênh lệch tới 15% giữa kết quả tốt nhất và tệ nhất.
Điều mà các nhà nghiên cứu của Apple phát hiện ra, đấy là càng đổi dữ kiện số trong các bài toán của các em học sinh trung học, thì LLM lại càng dễ có nguy cơ làm toán sai.
Chênh lệch như thế này, giữa cả những lần chạy benchmark GSM-Symbolic lẫn kết quả tính toán những bài toán trong gói GSM8K cũng dễ khiến mọi người bất ngờ. Các nhà nghiên cứu chỉ ra rằng, số bước nội suy mô phỏng tư duy toán học LLM cần thực hiện để giải quyết một bàn toán vẫn giữ nguyên.
Nhưng kết quả tính toán có sai lệch, lúc đúng lúc sai, tỷ lệ làm toán đúng không đồng đều của LLM cho thấy, những mô hình ngôn ngữ này không thực hiện tính toán tư duy một cách thật sự, mà thay vào đó “chỉ cố gắng chạy mô hình phân phối một cách phù hợp, căn chỉnh những câu hỏi và các bước giải quyết bài toán tương tự như trên những dữ liệu huấn luyện ban đầu của chúng.”
LLM dễ bị xao nhãng vì dữ liệu không liên quan
Để công bằng với những LLM mạnh nhất thế giới hiện nay, chênh lệch tỷ lệ làm toán một cách chính xác giữa những lần thử nghiệm benchmark làm toán là quá thấp. Lấy ví dụ tốt nhất trong số những mô hình mà các nhà nghiên cứu thử nghiệm là GPT-4o, tỷ lệ chỉ giảm từ 95.2% xuống 94.9%. Đấy vẫn là tỷ lệ tư duy toán học đúng rất cao, bất chấp việc “tư duy toán học” này không dựa trên nguyên lý mà chỉ dựa trên những ví dụ nó đã được học.
Và khi các nhà nghiên cứu thêm vài bước tính toán yêu cầu LLM tư duy, đương nhiên tỷ lệ trả lời đúng của LLM cũng giảm một cách đột ngột.
Còn trong khi đó, những LLM vận hành local thì có kết quả tệ hơn khá nhiều khi bước thứ 2 của thử nghiệm được triển khai. Ở bước này, các nhà nghiên cứu phát hiện ra một điều như thế này, có thể liên quan tới cách chúng ta viết prOmpt để yêu cầu AI trả lời. Khi thêm những câu tuyên bố tưởng chừng có liên quan tới dữ kiện bài toán những thực tế không có giá trị gì, mọi thứ trở nên tệ hơn nhiều đối với những LLM. Lấy ví dụ benchmark GSM-NoOp, một câu hỏi về số trái cây được hái trong nhiều ngày (đơn giản là tính nhân và tính cộng) đã được thêm một đoạn theo kiểu “5 trái trong số đó nhỏ hơn mức trung bình.”
Số 5 vô giá trị trong bài toán kia bỗng nhiên khiến những LLM không thể trả lời đúng những bài toán ấy. Có thể coi đây là “cá trích đỏ” khiến LLM bị phân tâm và xao nhãng. Hệ quả là tỷ lệ trả lời đúng những bài toán của các LLM được thử nghiệm giảm từ 17.5% lên tới… 65.7%. Chính kết quả này càng củng cố cho nhận định rằng, LLM không thể tư duy mà chỉ dự đoán “pattern matching” sau quá trình huấn luyện, rồi sau đó là “chuyển đổi lời nói thành tác vụ mà chẳng hiểu ý nghĩa của chúng.”
Lấy ví dụ, vẫn là bài toán hái trái cây ở trên, hầu hết mọi mô hình đều cố trừ con số “5 trái kiwi nhỏ hơn” khỏi tổng số. Các nhà nghiên cứu cho rằng, lý do là “bộ dữ liệu huấn luyện mô hình bao gồm những ví dụ tương tự, phải chuyển đổi câu nói thành phép tính trừ.”
“Hiểu toán”
Kết quả nghiên cứu này thực tế không phải thứ quá mới mẻ và gây chấn động ngành nghiên cứu AI toàn cầu. Trước đó đã từng có những nghiên cứu nói rằng LLM thực sự không làm những bước tư duy logic, mà chỉ bắt chước kết hợp với nội suy xác suất dựa trên dữ liệu gần giống nhất mà nó biết.
Nhưng nghiên cứu này lại mô tả rằng, chỉ cần thêm một hai câu hay chỉ cần 1 dữ kiện thêm cũng đã đủ khiến LLM bị xao nhãng, bị loạn, rồi làm sai những bài toán cực kỳ đơn giản trong mắt con người. Hệ quả là, khi LLM không thể hiểu những nền móng lý thuyết toán học và tư duy logic cơ bản, rất khó yêu cầu nó có khả năng làm việc như những gì các tập đoàn đang quảng cáo.
Và đương nhiên, dữ liệu huấn luyện càng nhiều, LLM sẽ càng có tỷ lệ nội suy xác suất ra những câu trả lời đúng. Trong nghiên cứu, các kỹ sư của Apple viết:
“Một trong những nguyên nhân GPT-4 của OpenAI có kết quả ấn tượng trong việc nội suy văn bản, là vì mô hình này đã chạm được tới ngưỡng kích thước đủ lớn để ghi nhớ đủ thông tin dữ liệu trong gói dữ liệu huấn luyện, rồi tạo ra cảm giác trong mắt con người rằng có vẻ như nó thực sự hiểu cách khoa học tự nhiên vận hành.
Nhưng thực tế, một khía cạnh khiến mô hình này thành công là nó biết nhiều kiến thức hơn hẳn so với hầu hết mọi người, rồi gây ấn tượng với chúng ta bằng cách kết hợp những khái niệm theo cách mới. Cứ đủ dữ liệu huấn luyện và sức mạnh điện toán, ngành công nghiệp AI có thể chạm tới được khái niệm gọi là ‘ảo tưởng AI có hiểu biết’, từ đó tạo ra được hình ảnh, thậm chí video nhìn rất giống thật.”
Chuyên gia về AI Gary Marcus cho rằng, bước tiến lớn tiếp theo của công nghệ AI sẽ chỉ đến khi những neural network có thể tích hợp những “thao tác xử lý ký hiệu, trong đó một số kiến thức được mô tả theo cách cực kỳ trừu tượng dưới dạng các biến và phép toán trên các biến đó, giống những gì chúng ta thấy trong môn đại số và lập trình.”
Còn cho tới khi ấy, AI sẽ chỉ có thể “lý luận” bằng cách bắt chước lại mọi ví dụ nó đã được học, đôi khi giải toán còn thua cả máy tính Casio của các em học sinh.
Tin xem thêm









nội dung mới